샤딩을 사용하는 경우
- 사용 가능한 메모리를 늘릴때
- 사용 가능한 디스크 공간을 늘릴때
- 서버의 부하를 줄일때
- 한 개의 mongod가 다룰 수 있는 처리량보다 더 많이 데이터를 읽거나 쓸때
샤딩이 필요한 시점을 결정하는 데 모니터링이 중요하다. 어떤 항목을 프로비저닝(provisioning)할지 찾고, 복제 셋 전환 방법과 시기를 미리 계획해야 한다.
프로비저닝(provisioning)
사용자의 요구에 맞게 시스템 자원을 할당, 배치, 배포해 두었다가 필요 시 시스템을 즉시 사용할 수 있는 상태로 미리 준비해 두는 것을 말한다.
서버 시작
클러스터를 생성하려면 먼저 필요한 프로세스를 모두 시작해야한다.
- mongos, 샤드 설정
- 구성 서버 : 클러스터 구성을 저장하는 일반 mongod 서버
- 클러스터 구성 : 샤드를 호스팅하는 복제 셋, 샤딩된 컬렉션, 각 청크가 위치한 샤드 등
몽고DB 3.2 부터는 복제 셋을 구성 서버로 사용할 수 있다. 복제 셋은 구성 서버에서 사용하는 기존 동기화 메커니즘을 대체한다.

구성 서버
구성 서버는 클러스터의 두뇌로, 어떤 서버가 무슨 데이터를 갖고 있는지에 대한 모든 메타 데이터를 보유한다. 따라서 구성 서버를 가장 먼저 설정해야한다. 운영 배포에서 구성 서버 복제 셋은 3개 이상의 멤버로 구성해야한다. 각 구성 서버는 지리적으로 분산된 별도의 물리적 장비에 있어야한다.
mongos가 구성 서버로부터 구성을 가져온다.
1) 구성 서버는 mongos 프로세스에 앞서 시작해야한다.
$ mongod --configsvr --replSet configRS --bind_ip localhost,198.51.100.51
$ mongod --configsvr --replSet configRS --bind_ip localhost,198.51.100.52
$ mongod --configsvr --replSet configRS --bind_ip localhost,198.51.100.53
2) 구성 서버를 복제 셋으로 시작한다. mongo 셸을 복제 셋 멤버중 하나에 연결한다.
$ mongo --host <호스트명> --port <포트>
3) rs.initiate() 보조자를 사용한다.
> rs.initiate(
{
id: "configRS"
configsvr: true,
members: [
{id : 0, host : "cfg1.example.net:27019"},
{id : 1, host : "cfg2.example.net:27019"},
{id : 2, host "cfg3.example.net:27019"}
]
}
)| 옵션 | 설명 |
| _id | 복제 셋 이름 (ConfigRS) |
| --configsvr | mongod를 구성 서버로 사용하겠다는 의미 이 옵션으로 실행되는 서버에서 클라이언트(즉 다른 클러스터 구성요소)는 config와 admin 이외의 데이터베이스에 데이터를 쓸 수 없다. |
admin 데이터베이스
- 인증 및 권한 부여와 관련된 컬렉션과, 내부용 기타 system.* 컬렉션을 포함한다.
config 데이터베이스
- 샤딩된 클러스터 메타데이터를 보유하는 컬렉션을 포함한다.
- 청크 마이그레이션/청크 분할 후처럼 메타데이터가 변경될 때 config 데이터베이스에 데이터를 쓴다.
mongos 프로세스
3개의 구성 서버가 실행중이면 애플리케이션이 접속할 mongos 프로세스를 시작하자.
mongos 프로세스가 구성 서버들의 위치를 알아야 하므로 항상 --configdb 옵션으로 mongos 프로세스를 시작해야한다.
$ mongos --configdb \
configRS/cfg1.example.net:27019 \
cf92.example.net:27019,cfg3.example.net:27019 \
--bind_ip localhost,198.51.100.100 --logpath /var/log/mongos.log1) mongos는 기본적으로 port 27017로 실행한다.
2) 로그를 안전하게 저장하기 위해 --logpath를 설정한다.
복제 셋으로 샤딩 추가
이제 샤딩을 추가할 준비가 됐다. 이미 복제 셋이 있는 경우와 처음부터 시작하는 경우가 있다.
▶ 기존 복제 셋이 있는 경우
애플리케이션에 이미 복제 셋이 있다면 해당 셋이 첫번째 샤드가 된다. 복제 셋을 샤드로 전환하려면 멤버의 구성을 약간 수정한 후, mongos에게 샤드를 구성할 복제 셋을 찾는 방법을 알려야 한다.
ex) svr1.example.net, svr2.example.net, svr3.example.net에 rs0이라는 복제 셋이 있으면 먼저 mongo 셸을 사용해 멤버 중 하나에 연결한다.
$ mongo srv1.example.net
아래 명령어를 통해 어떤 멤버가 프라이머리고, 어떤 멤버가 세컨더리인지 확인할 수 있다.
> rs.status()몽고DB 3.4부터 샤드용 mongod 인스턴스는 반드시 --shardsvr 옵션으로 구성해야한다. 구성 파일 설정 sharding.clusterRole 혹은 명령행 옵션 --shardsvr을 통해 구성한다.
샤드로 변환하는 과정에서 복제 셋의 각 멤버에 대해 아래 작업을 수행해야한다.
1) 먼저 --shardsvr 옵션을 사용해 각 세컨더리를 차례대로 재시작한다.
2) 프라이머리를 단계적으로 강등한다. (> rs stepDown())
3) -shardsvr 옵션을 사용해 재시작한다
1) 세컨더리를 종료한 후 아래와 같이 재시작한다.
$ mongod --replSet "rs0" --shardsvr --port 27017
--bind_ip localhost,<멤버의 IP 주소>--bind_ip 매개변수에 각 세컨더리의 올바른 IP 주소를 사용해야한다.
2) mongo 셸을 프라이머리에 연결한다.
$ mongo m1.example.net
3) 그리고 프라이머리를 강등한다.
> rs.stepDown()
4) 그런 다음 --shardsvr 옵션을 사용해 이전 프라이머리를 재시작한다.
$ mongod --replSet "rs0" --shardsvr --port 27017
--bind_ip localhost,<이전 프라이머리의 IP 주소>
이제 복제 셋을 샤드로서 추가할 준비가 됐다.
1) mongo 셸을 mongos의 admin 데이터베이스에 연결하자.
$mongo mongos1.example.net:27017/admin
2) sh.addShard() 메서드를 사용해 클러스터에 샤드를 추가한다.
> sh.addShard(
"rs0/svr1.example.net:27017,svr2.example.net:27017,svr3.example.net:27017")
복제 셋의 모든 멤버를 지정할 수 있지만 그럴 필요는 없다. mongos는 시드 목록에 포함되어있지 않은 멤버를 자동으로 감지한다.
3) sh.status()를 실행하면 몽고DB가 곧바로 샤드를 나열한다.
rs0/svr1.example.net:27017,svr2.example.net:27017,svr3.example.net:27017복제 셋 이름 rs0은 이 샤드의 식별자가 된다. 샤드를 제거하거나 데이터를 샤드로 옮기려면 rs0를 사용해 설명한다. 복제 셋의 멤버쉽과 상태는 시간이 흐르면 바뀔 수 있으므로 특정한 서버(예를 들면 svr1.example.net)을 사용하는 것보다 낫다.
복제 셋을 샤드로 추가했으면 애플리케이션이 복제 셋 대신에 mongos에 접속하게 할 수 있다. mongos는 클라이언트 라이브러리처럼 애플리케이션의 장애 조치를 자동으로 처리하며, 사용자에게 오류를 전달한다.
용량 추가
용량을 추가하려면 샤드를 추가해야한다. 복제 셋을 생성해 빈 샤드를 새로 추가하고, 기존 샤드들과 다른 이름을 갖게해야한다. 복제 셋이 초기화되고 프라이머리를 갖게되면, mongos를 통해 addShard 명령어를 실행해 클러스터에 추가하고, 새로운 복제 셋의 이름과 호스트를 시드로 지정한다.
샤드가 아닌 기존 복제 셋이 여러개 있으면, 데이터베이스 이름이 겹치지 않는 한 클러스터에 새로운 샤드로 추가할 수 있다.
데이터 샤딩
몽고DB는 데이터를 어떻게 분산할지 알려주기 전에는 자동으로 데이터를 분산하지 않는다. 분산하려는 데이터베이스와 컬렉션을 명시적으로 알려줘야 한다.
예를들어 music 데이터베이스의 artists 컬렉션을 "name"키로 샤딩한다고 가정하자. 우선 music 데이터베이스의 샤딩을 활성화한다.
> sh.enableSharding("music")
데이터베이스는 항상 데이터베이스 내 컬렉션보다 먼저 샤딩해야 한다.
데이터베이스 수준에서 샤딩을 활성화하고 나면 sh.shardCollection을 실행해서 컬렉션을 샤딩할 수 있다.
> sh.shardCollection("music.artists", {"name" : 1})이제 artists 컬렉션은 "name" 키로 샤딩된다. 기존 컬렉션을 샤딩하려면 "name" 필드에 인덱스가 있어야한다. 그러지 않으면 shardCollection 호출은 오류를 반환한다.
샤딩할 컬렉션이 아직 존재하지 않으면 mongos가 자동으로 샤드 키 인덱스를 만든다. shardCollection 명령은 컬렉션을 청크로 나눈다.
청크
몽고DB가 데이터를 옮기는데 사용하는 단위
명령 실행이 성공하면 몽고DB는 클러스터의 샤드에 컬렉션을 분산한다.
몽고DB의 클러스터 데이터 추적 방법
각 mongos는 샤드 키가 주어지면, 도큐먼트를 어디서 찾을지 항상 알아야한다. 몽고DB는 주어진 샤드 키 범위 내에 있는 도큐먼트를 청크로 나누며, 하나의 청크는 항상 하나의 샤드에 위치하므로 몽고DB는 샤드에 매핑된 청크의 작은 테이블을 가진다.
예시
컬렉션의 샤드 키가 {"age" : 1}이면, 하나의 청크는 "age" 필드가 3과 17 사이인 모든 도큐먼트가 된다. mongos는 {"age" : 5} 쿼리 요청을 받으면 청크 3과 17 사이가 있는 샤드에 쿼리를 라우팅한다.
청크가 일정 크기까지 커지면 몽고DB는 자동으로 두개의 작은 청크로 나눈다. 그리고 3~15, 12~17처럼 범위가 겹치는 청크는 가질 수 없다.
도큐먼트는 항상 단 하나의 청크에만 속한다. 그 결과 배열 필드를 샤드 키로 사용할 수 없다. 몽고DB가 배열에 여러개의 인덱스 항목을 만들기 때문이다.
청크 범위
각 청크는 포함되는 범위에 의해 설명된다. 새로 샤딩된 컬렉션은 단일 청크로부터 출발하며 모든 도큐먼트는 이 청크에 위치한다. 청크 범위는 $minKey ~ $maxKey로 표시되며, 값은 음의 무한대와 양의 무한대 사이다.
청크가 커지면 몽고DB는 자동으로 음의 무한대에서 <value>(미포함), <value>(포함)에서 양의 무한대까지의 범위를 갖는 두개의 청크로 나눈다.
예시
"age"로 샤딩했다고 가정하자. "age"가 3과 17 사이인 모든 도큐먼트는 하나의 청크, 즉 3 <= "age" < 17에 포함된다. 이를 나누면 2개의 범위가 되며, 한 청크는 3 <= "age" < 12이고 다른 청크는 12 <= "age" <17이다. 이때 12를 분할점(split point)이라 불린다.
청크 정보는 config.chunks 컬렉션에 저장된다.
복합 샤드키의 경우 청크 범위
복합 샤드 키의 경우, 샤드 범위는 두 개의 키로 정렬할 때와 동일한 방식으로 작동한다.
예시
{"username" : 1, "age" : 1}에 샤드 키가 있다고 가정하자.
1) 사용자명을 갖는 누군가가 위치한 청크는 쉽게 찾을 수 있다.
2) 나이만 주어지면 mongos는 모든 청크 혹은 대부분의 청크를 확인해야한다.
- 올바른 청크에 나이로 쿼리하려면, {"age" : 1, "username" : 1}과 같이 역순의 샤드 키를 사용해야한다.
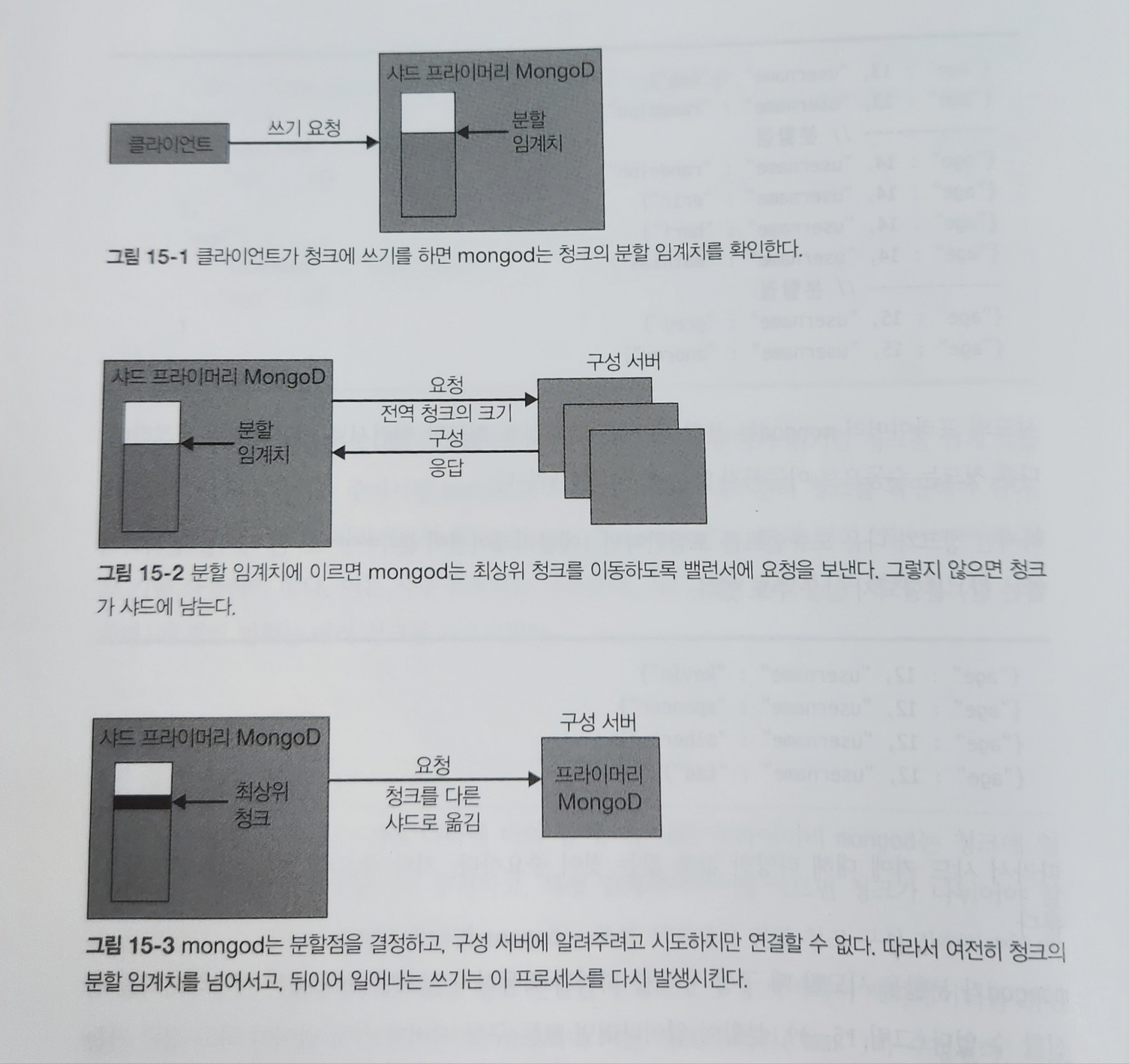
청크 분할
각 샤드의 프라이머리 mongod는 청크에 얼마나 많은 데이터가 삽입됐는지 추적하고, 특정 임계치에 이르면 청크가 나뉘어야 할지 확인한다.
1) 청크가 나뉘어야 한다면 mongod는 구성 서버에서 전역 청크 구성값을 요청한다.
2) 그런 다음 청크 분할을 수행한다.
3) 구성 서버에서 메타데이터를 갱신한다.
4) 새 청크 도큐먼트가 구성 서버에 생성되며 이전 청크의 범위("max")가 수정된다.
5) 샤드의 최상위 청크인 경우 mongod는 청크를 다른 샤드로 이동하도록 밸런서에 요청한다.
샤드 키가 단조롭게 증가하는 키를 사용하는 경우 샤드가 과부하 상태가 되는 것을 방지하기 위함이다. 청크는 샤드 키 값이 변경되는 도큐먼트를 기준으로만 분할할 수 있다. 예를들어, 샤드 키가 "age"이면 청크는 샤드 키(age)가 바뀌는 시점에서 분할된다.
mongod가 분할을 시도할때 구성 서버 중 하나가 작동하지 않으면 mongod는 메타데이터를 갱신할 수 없다. 분할이 일어나려면 모든 구성 서버가 살아 있어야 하고 접근 가능해야 한다. mongod가 청크에 대한 쓰기 요청을 계속 받으면, 계속해서 청크를 분할하려고 시도하다가 실패한다.
분할 소동(split storm)
mongod가 반복적으로 청크 분할을 시도하고 실패하는 과정을 말한다.
분할 소동을 방지하는 유일한 방법은 가능한 시간만큼 구성 서버가 살아있고 정상이게 하는것이다.
밸런서
밸런서는 데이터 이동을 책임진다. 주기적으로 샤드 간의 불균형을 체크하다가, 불균형이면 청크를 이동하기 시작한다. 몽고DB 3.4 이후 버전에서 밸런서는 구성 서버 복제 셋의 프라이머리 멤버에 있다.
밸런서는 각 샤드의 청크 수를 모니터링하는 구성 서버 복제 셋의 프라이머리에서 백그라운드 프로세스다. 샤드의 청크 수가 특정 마이그레이션 임계치에 이를때만 활성화된다.
mongos 로그 오류 : unable to setShardVersion
데이터 이동이 완료될때까지 모든 읽기와 쓰기는 이전 청크로 전달되는데, 메타데이터가 갱신된 후에는 이전 위치의 데이터에 접근을 시도하는 모든 mongos 프로세스에 오류가 발생한다. 이때 mongos가 은밀히 오류를 처리하고 새로운 샤드에서 작업을 재시도하여 클라이언트에는 오류가 표시되지 않는다.
mongos가 위와 같은 오류를 받으면 구성 서버에서 데이터의 새로운 위치를 사렾보고, 청크 테이블을 갱신하고, 요청을 다시 시도한다. 그리고 클라이언트에 데이터를 반환한다.
'NoSQL' 카테고리의 다른 글
| [Redis 기본 개념] Redis의 자료구조와 커맨드 정리 (1) | 2023.11.23 |
|---|---|
| [몽고DB 완벽가이드] 샤드 키 선정 (0) | 2023.03.22 |
| [몽고DB 완벽가이드] 샤딩의 개념 (0) | 2023.03.17 |
| [MongoDB] database 생성 및 테스트 데이터 CRUD(INSERT, SELECT, UPDATE, DELETE) 실행해보기 (0) | 2022.08.14 |
| [MongoDB] MongoDB Altas Free버전 Compass 사용하기 (0) | 2022.08.14 |