Parallel Steps

- SplitState를 사용하여 여러개의 Flow들을 병렬적으로 실행하는 구조이다.
- 실행이 다 완료된 후 FlowExecutionStatus 결과들을 취합해서 다음 단계를 결정한다.
Job 생성
ParallelStepConfiguration.java
package com.project.springbatch._44_parallel;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.job.builder.FlowBuilder;
import org.springframework.batch.core.job.flow.Flow;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.core.step.tasklet.TaskletStep;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.TaskExecutor;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
/*
--job.name=parallelJob
*/
@RequiredArgsConstructor
@Configuration
public class ParallelStepConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job parallelJob() {
return jobBuilderFactory.get("parallelJob")
.incrementer(new RunIdIncrementer())
.start(parallelFlow1())
.split(parallelTaskExecutor()).add(parallelFlow2())
.end()
.listener(new ParallelStopWatchJobListener())
.build();
}
@Bean
public Flow parallelFlow1() {
TaskletStep step = stepBuilderFactory.get("step1")
.tasklet(parallelTasklet()).build();
return new FlowBuilder<Flow>("parallelFlow1")
.start(step)
.build();
}
@Bean
public Flow parallelFlow2() {
TaskletStep step1 = stepBuilderFactory.get("step2")
.tasklet(parallelTasklet()).build();
TaskletStep step2 = stepBuilderFactory.get("step3")
.tasklet(parallelTasklet()).build();
return new FlowBuilder<Flow>("parallelFlow2")
.start(step1)
.next(step2)
.build();
}
@Bean
public Tasklet parallelTasklet() {
return new ParallelCustomTasklet();
}
@Bean
public TaskExecutor parallelTaskExecutor(){
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(2);
executor.setMaxPoolSize(4);
executor.setThreadNamePrefix("parallel-thread-");
return executor;
}
}1) parallelJob() 메서드
@Bean
public Job parallelJob() {
return jobBuilderFactory.get("parallelJob")
.incrementer(new RunIdIncrementer())
.start(parallelFlow1())
.split(parallelTaskExecutor()).add(parallelFlow2())
.end()
.listener(new ParallelStopWatchJobListener())
.build();
}1) parallelFlow1 을 생성한다.
2) parallelFlow2를 생성하고 2개의 flow를 합친다.
3) .next()가 있다면, 위 1), 2)의 split 처리가 완료된 후 실행이 된다.
▶ parallelFlow1, parallelFlow2 를 병렬로 실행한다.
ParallelCustomTasklet.java
package com.project.springbatch._44_parallel;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
public class ParallelCustomTasklet implements Tasklet {
private long sum = 0;
// lock 을 만든다. lock 을 만들지 않고 이 스레드가 가지고있는 lock 을 사용해도 된다.
// 모든 객체들은 하나의 lock 을 가진다.
private Object lock = new Object();
@Override
public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception {
// Thread.sleep(1000);
synchronized (lock) {
for (int i = 0; i < 1000000000; i++) {
sum++;
}
// thread 이름 출력
System.out.println(String.format("%s has been executed on thread %s",
chunkContext.getStepContext().getStepName(),
Thread.currentThread().getName()));
System.out.println(String.format("sum : %d", sum));
}
return RepeatStatus.FINISHED;
}
}1) lock 객체 선언
private Object lock = new Object();
2) 동기화 synchronized(lock) {...}
synchronized (lock) {
for (int i = 0; i < 1000000000; i++) {
sum++;
}
// thread 이름 출력
System.out.println(String.format("%s has been executed on thread %s",
chunkContext.getStepContext().getStepName(),
Thread.currentThread().getName()));
System.out.println(String.format("sum : %d", sum));
}동기화블록 처리 하지않으면 각 스레드가 동시에 접근하기 때문에 sum이 이상한 값으로 출력된다.
우리가 병렬로 스레드를 실행할때 가장 이슈가 되는건 '동시성'의 문제다.
여러 쓰레드들이 공유 데이터에 접근하게되어, 공유 데이터에 쓰기 작업이 중복적(동시적)으로 발생하게 되면 원하는 값이 나오지 않는다.
숫자가 높을수록 CPU 연산이 오래걸리기 때문에 찰나의 작은 시간에 정확하지 않은 숫자들이 발생하여 동시성 이슈가 생긴다.
그래서 synchronized로 묶은 블록만큼은 하나의 스레드씩 동기화하여 처리되어야한다.
ParallelStopWatchJobListener.java
package com.project.springbatch._44_parallel;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
public class ParallelStopWatchJobListener implements JobExecutionListener {
@Override
public void beforeJob(JobExecution jobExecution) {
}
@Override
public void afterJob(JobExecution jobExecution) {
long time = jobExecution.getEndTime().getTime() - jobExecution.getStartTime().getTime();
System.out.println("time : " + time);
}
}
Job 수행결과
step2 has been executed on thread parallel-thread-1
sum : 1000000000
step1 has been executed on thread parallel-thread-2
sum : 2000000000
step3 has been executed on thread parallel-thread-1
sum : 3000000000
time : 19004
디버깅
1) FlowBuilder.java > start()

2) FlowBuilder.java > createState()
"parallelStep1"

states 객체에 put되어있다.
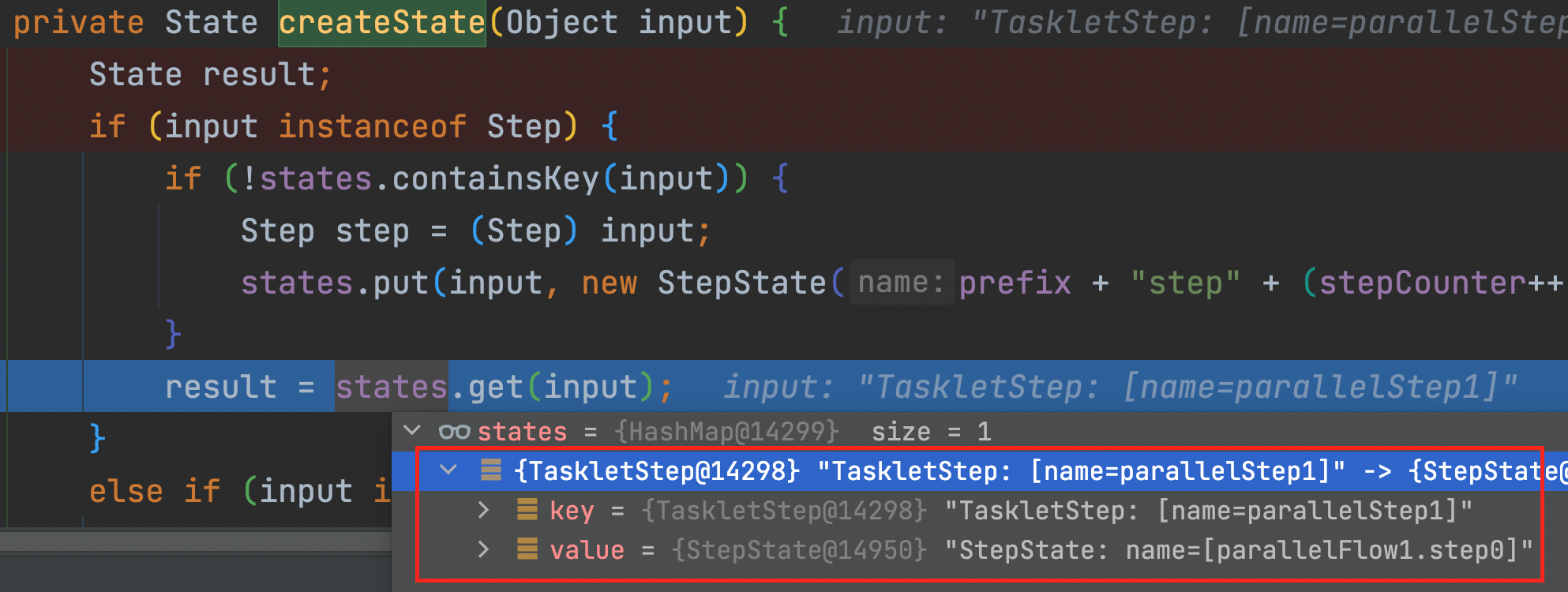
"parallelFlow1"
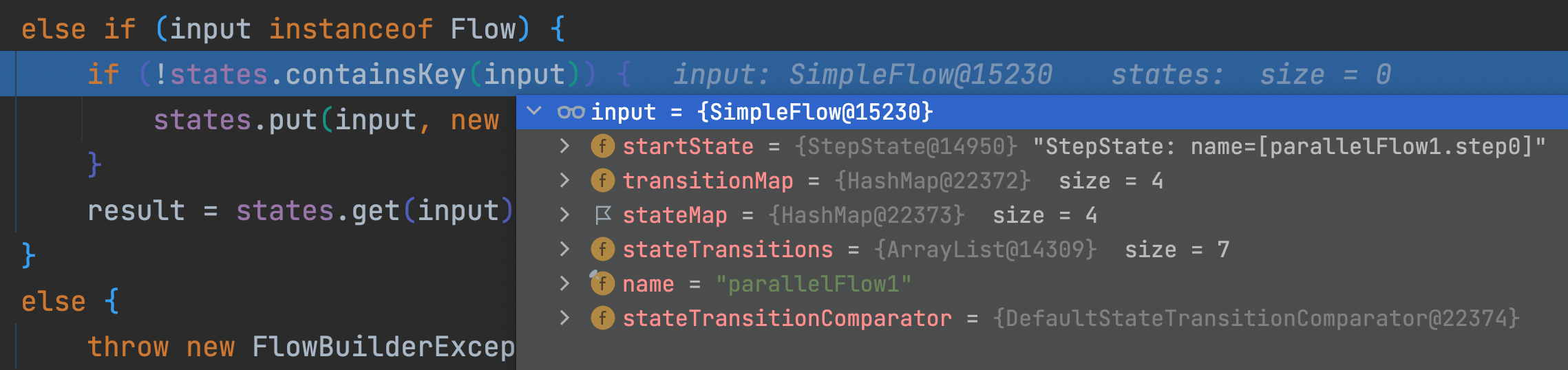
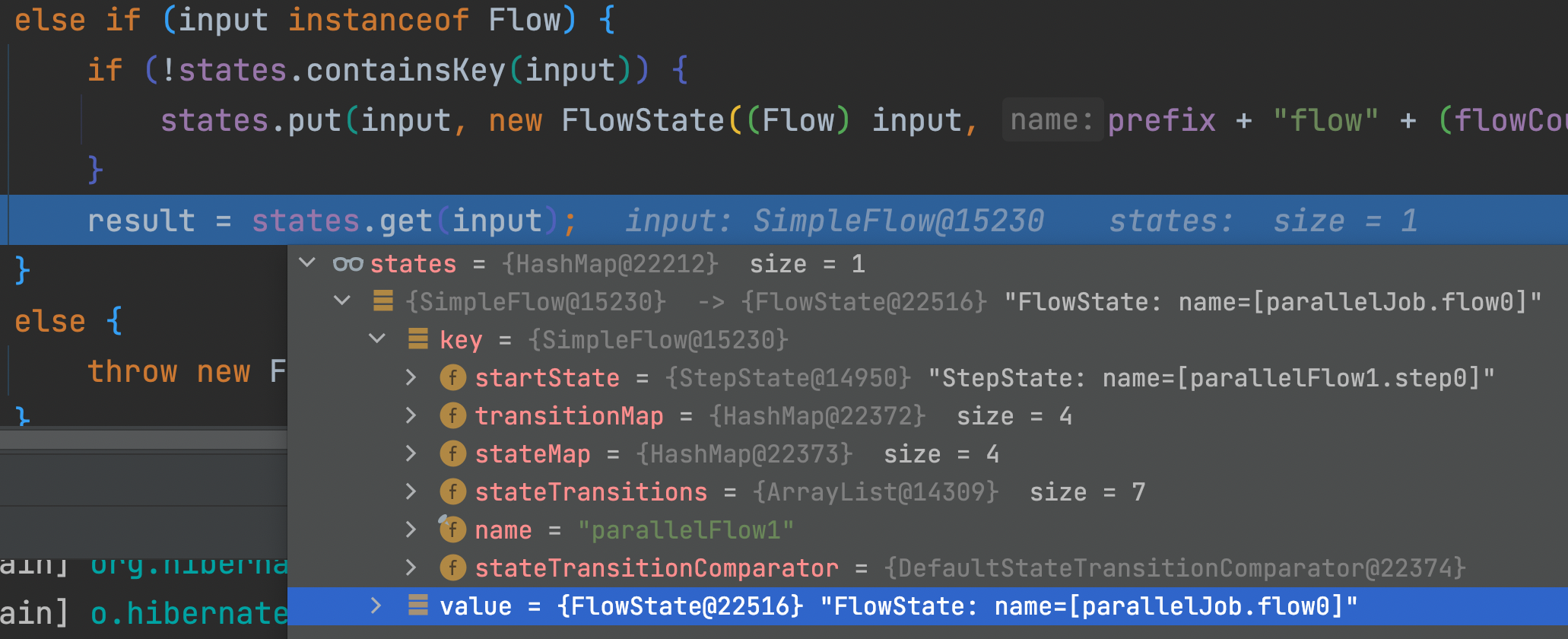
3) JobFlowBuilder.java

4) FlowJobBuilder.java > start()

5) FlowBuilder.java > split()

6) FlowBuilder.java > createState()
"parallelStep2"

"parallelStep3"

7) SimpleFlow.java > resume()
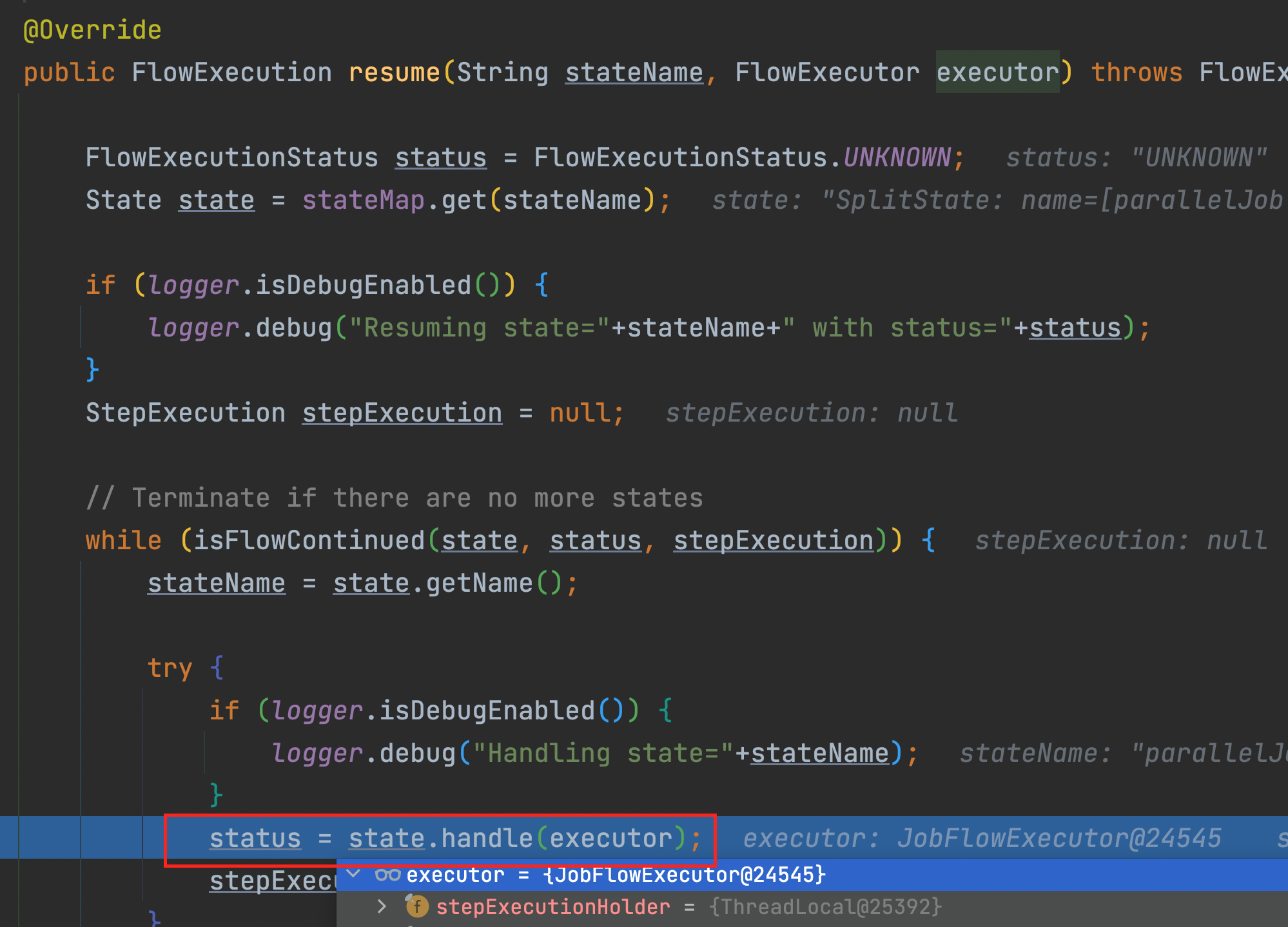
8) SplitState.java
@Override
public FlowExecutionStatus handle(final FlowExecutor executor) throws Exception {
// TODO: collect the last StepExecution from the flows as well, so they
// can be abandoned if necessary
Collection<Future<FlowExecution>> tasks = new ArrayList<>();
for (final Flow flow : flows) {
final FutureTask<FlowExecution> task = new FutureTask<>(new Callable<FlowExecution>() {
@Override
public FlowExecution call() throws Exception {
return flow.start(executor);
}
});
tasks.add(task);
try {
taskExecutor.execute(task);
}
catch (TaskRejectedException e) {
throw new FlowExecutionException("TaskExecutor rejected task for flow=" + flow.getName());
}
}
Collection<FlowExecution> results = new ArrayList<>();
// Could use a CompletionService here?
for (Future<FlowExecution> task : tasks) {
try {
results.add(task.get());
}
catch (ExecutionException e) {
// Unwrap the expected exceptions
Throwable cause = e.getCause();
if (cause instanceof Exception) {
throw (Exception) cause;
} else {
throw e;
}
}
}
return doAggregation(results, executor);
}flows 객체의 갯수만큼 반복문을 돌아, 스레드가 생성되어 execute(task)로 실행된다.
flows 안에는 flow1, flow2 가 있고 이를 병렬 실행한다.
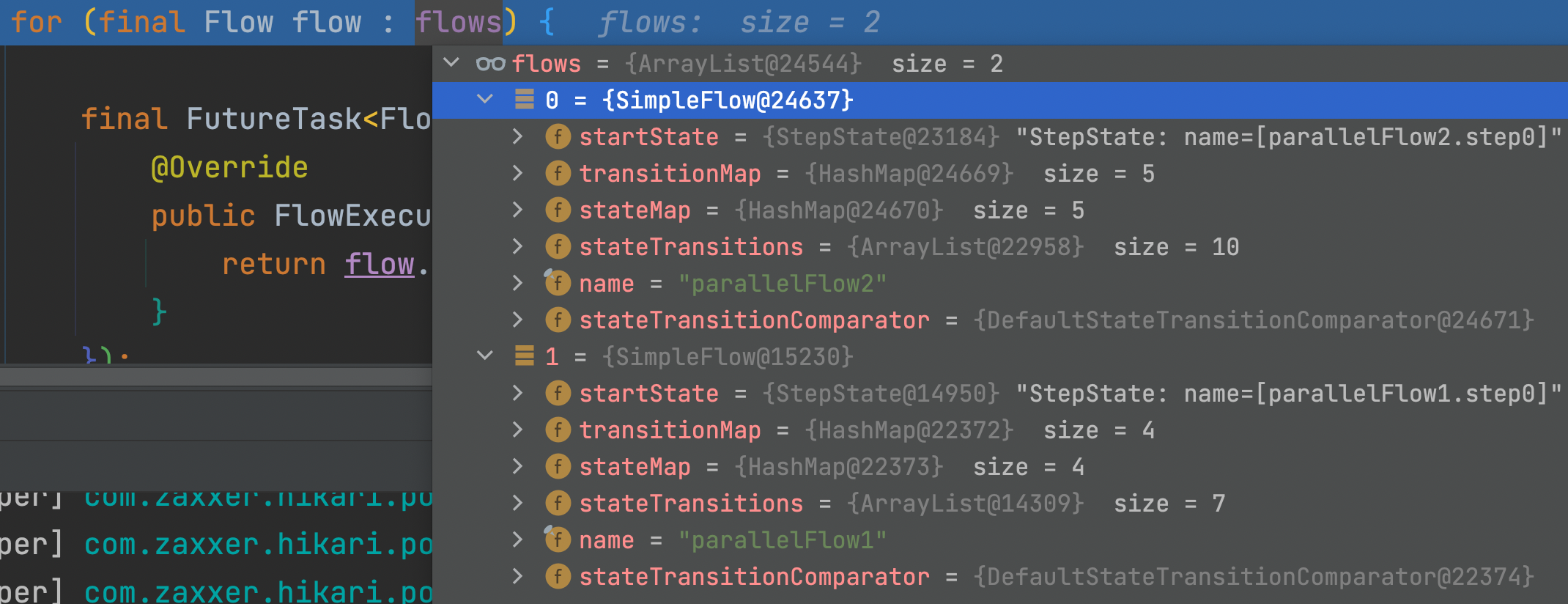
9) SplitState.java > doAggregation()

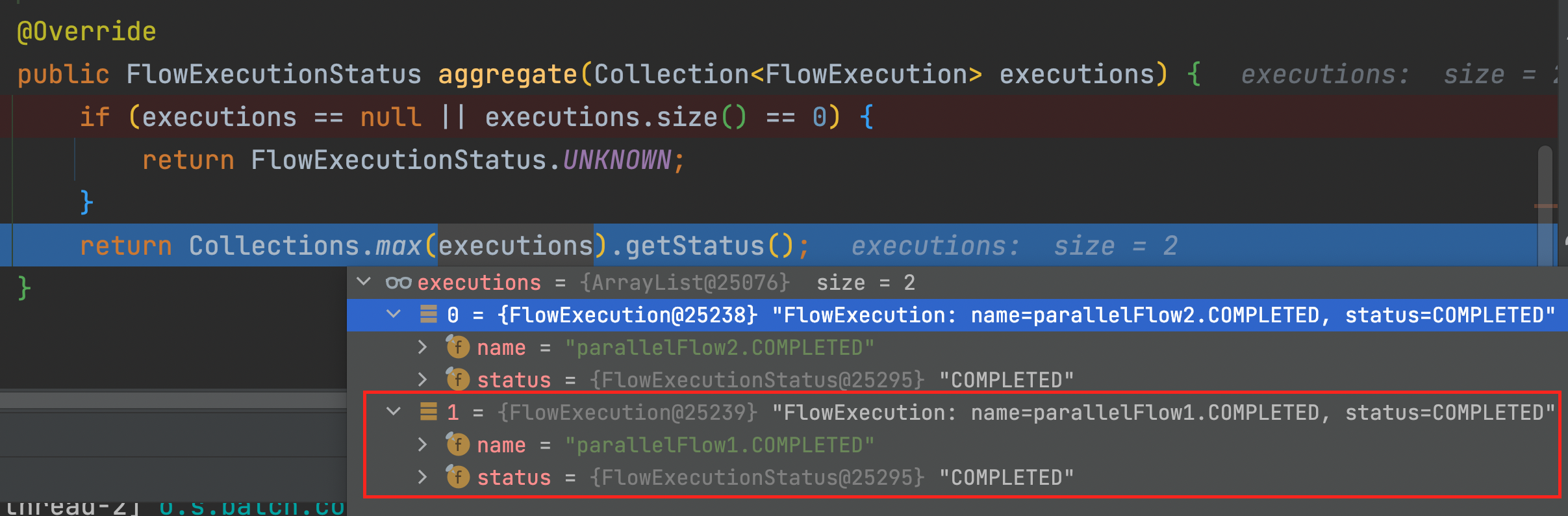
10) MaxValueFlowExecutionAggregator.java > aggregate()
최종적인 상태를 체크한다.
'Spring Batch' 카테고리의 다른 글
| [SpringBatch 실습] 33. 스프링 배치 SynchronizedItemStreamReader로 thread-safe 설정하기 (0) | 2022.07.13 |
|---|---|
| [SpringBatch 실습] 32. 스프링 배치 Partitioning(파티셔닝) Job 수행하여 분석 (0) | 2022.07.12 |
| [SpringBatch 실습] 30. 스프링 배치 MultiThread(멀티 스레드) Job 수행하여 분석 (0) | 2022.07.07 |
| [SpringBatch 실습] 29. 스프링 배치의 단일 스레드 vs 멀티 스레드 Job 수행하여 분석 (0) | 2022.07.06 |
| [SpringBatch 실습] 28. ItemReaderAdapter (0) | 2022.07.05 |